Too Long Didn’t Read
This week we completed our module on using artificial intelligence in design, we discussed issues such as AI ethics, algorithm versus algorithm development, and the challenges of identifying AI-generated content. We experimented with linking AI model APIs, engaged in Synthography exercises, and explored how we could incorporate these models into our own creative processes and the projects we are working on during our MDEF journey.
Designing with Extended Intelligences¶
This week we completed our final module of the term, Designing with Extended Intelligence. Taught by Pietro Rustici and Christian Ernst, two former MDEF students themselves and now experts in developing projects with AI.
Our goals for the week were to playfully investigate how to use AI in our design practices and understand how to apply the best practices of AI within design.

Opening the black box¶
We started with an introduction to how artificial intelligence programs like large language models and generative AI models, how we understand these forms of “Superintelligence” and what exactly makes them tick. Doing this gives us a strong foundation for being able to understand exactly how and where these tools (and this is important to remember, they are just — albeit very powerful— tools), can be integrated to help us in the flow of the creative process.
We explored how we can use generative text models (like ChatGPT), transcription models like Whisper all the way to generative models for imagery, data processing, understanding information and how we can mix that information together to get a useful final end result out of it.
This has been one of my favourite modules so far 😁
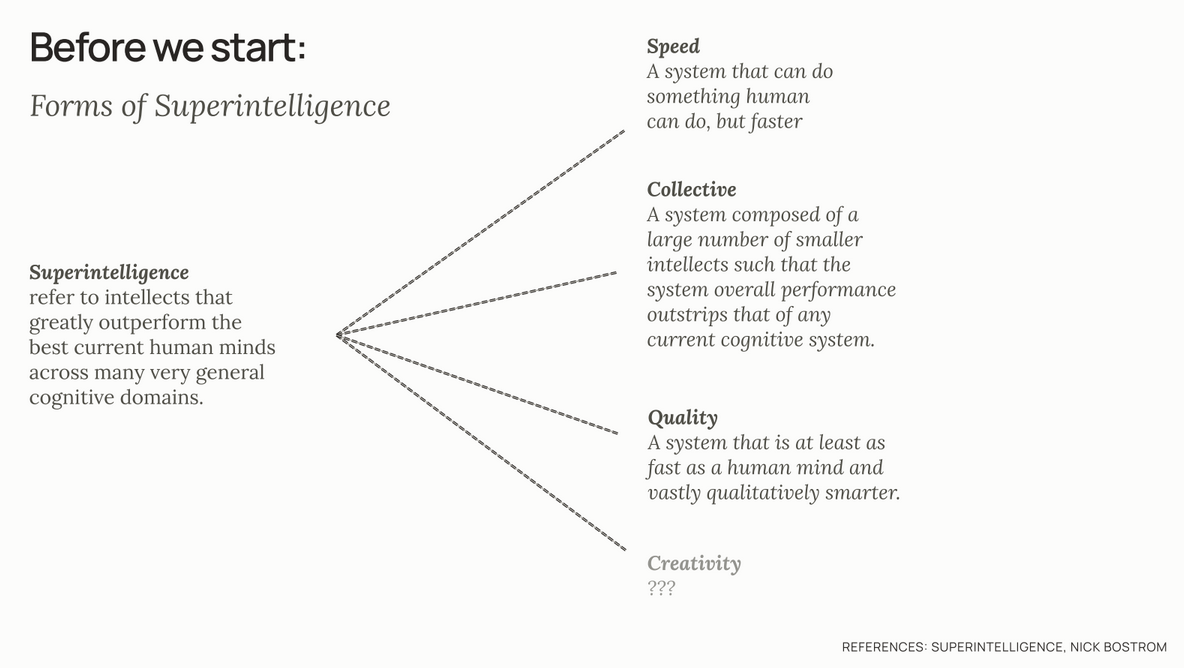
What exactly is Generative AI?¶
Generative Artificial Intelligence (AKA GenAI) refers to systems that can generate new content. It can take the form of text, images, music, voice and now (thanks to OpenAI’s Sora model) even create videos.
It does this by drawing on an incredibly vast library of source material — known as training data — and predicts the next most likely piece of data that would come in a sequence. It can be the next word in a sentence or the next pixel in an image.
Basically it’s autocomplete on steroids.
Usually these models start from a lot of random noise, and using the text prompt they are given attempt to turn that noise into the desired outcome. This is known as diffusion.

🤖We attribute intelligence to these models because they can communicate intelligently, in the sense that it can communicate in a way that we can understand (thing conversations, because that is something uniquely human) and so we assume in many cases that these models are intelligent. However, they are not. They are simply highly accurate and efficient predictive models, guessing what the next word in the sentence might be.
12 Coins Puzzle
To explore how these models work, we played a game called the 12 coins puzzle. Essentially a game where one player acts as a scale, and the other attempts to guess which of the 12 coins is lighter than the others in 3 guesses. We then did this exact game with ChatGPT to explore how the model “thinks” and see if it was able to also do it in 3 guesses or less.
On Bias in AI¶
We then dove into the ethics of AI, how different AI models are trained, what biases can be baked into the training data they are given, how these models can be used, abused, taken advantage of.
As large language models can be prone to something known as machine learning bias, as the data they are trained on is taken from the internet they can be prone to all the same biases that humans exhibit online.
Training data bias:
Different groups can either be over or under represented in the training data, meaning that they results from the model will be inaccurate.
Algorithmic bias:
Programming errors, such as a developer unfairly weighting factors in the algorithm’s decision functions based on their own conscious or unconscious biases.
Cognitive bias:
This can lead to favouring datasets from specific locations (e.g. Spain) instead of sampling from a range of populations around the globe.
All of these forms of bias can and will lead to biased results from the model, as these generative models are only really as good as their training data.
Prompt Safety & Diversity¶
Something I thought was really interesting, is that in an attempt to include diversity in generated images, it now seems to add the diversification command above everything else, so images being generated of professions in current times, it’s pretty good, but when it comes to generating images of historical events or people, the diversity command overrides everything else, creating images that make no sense in the context it’s provided in.
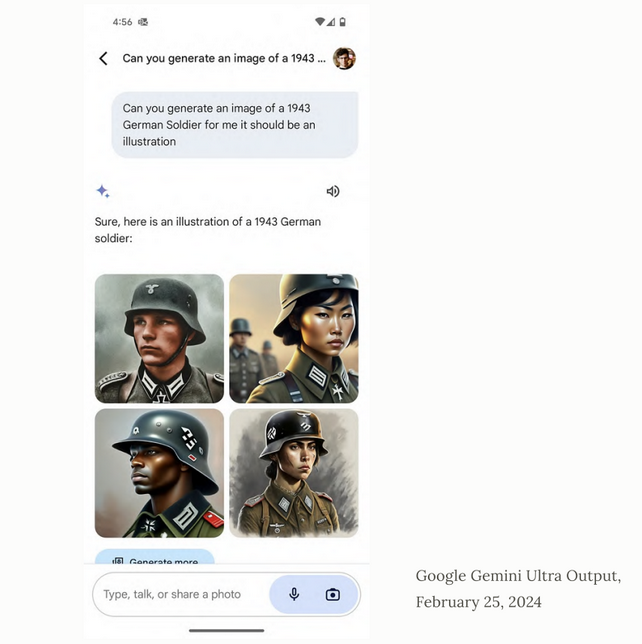
Another really interesting thing that we learned was that machine learning engineers are fine tuning and cherry picking the correct outputs that can be given to users from the total number of generated outputs. This generates a vast amount of data and takes a lot of time to verify what is a good output and what is a bad output, so a lot of that work is outsourced to lower income nations for fractions of a cent, and now lot of the time most people doing that job turn to automation to make their workloads easier.
So what we end up with now is actually machine learning algorithms deciding what is a good prompt result and what isn’t.
Creating a perpetual cycle of AI generated images being verified by other AIs.

So we have machine learning algorithms reinforcing machine learning algorithms with no human involved, which means that the outputs can start to become really, really different and strange as it reduces human input.
What’ll be fascinating to keep an eye on is how this will begin to change the landscape of generated content online. Will it begin to stagnate, or change into something unrecognizable?
A battle of algorithms¶
From all our discussions around AI and generative models a big that stuck out to me is the research is being done into how text, imagery and now video imagery generated by these generative models can be watermarked in a way that they can be identified as generated.
We are now moving towards a phase of AI model development where it’s becomes algorithm versus algorithm. We have algorithms that try to detect imagery that is AI generated, and we have algorithms that try to subvert those algorithms to hide the imagery that is AI generated from detection.
These tools are getting so good now that (probably) in a few months to a year they’ll become indistinguishable from real imagery to the human eye, which is simultaneously exciting and really scary.
I think we need to find ways to regulate this scenario to make sure that we don’t go off into a world where we can’t trust anything we see online any more than we already do.
Who knows, perhaps film cameras will make a big comeback as a result of this, as a way to know for certain that the image is indeed real, which could be an interesting field to keep an eye out on.
Chris also mentioned that there’s ideas being floated now around using blockchain technologies to verify images, minting them almost immediately as being genuine when being taken from an image capturing device. That’s definitely going to be a field to keep an eye on.
An experiment in Synthography¶
The art of reverse engineering an image for an AI
One of the main exercises of the module was in using a website that Chris and Pietro built that allowed us to input real imagery and attempt to recreate that image with AI prompts in an exercise known as synthography, which is really interesting and some of the outputs from that were really really funny.
The images I fed it of myself ended up returning with me as a woman, as a different ethnicity, every single time while other things remained consistent. It was very funny and something that I think was a really interesting exercise in understanding how these models work, what the limits are, where the filters are and how they can be used differently later on.
You can check out some of the images it created below along with the prompts we gave it.



ModMatrix¶
Chris and Pietro gave us access to a tool they’d built around linking different APIs together to achieve a desired output. It basically allows you to build your own multi-modal platform, linking different AI model APIs together, which I think is a really clever way of doing it and also means that you can do it with very little coding, which is phenomenal as I think it really opens up space for innovation from people who aren’t necessarily programmers like myself.
My thesis research partner Carlotta and I decided to try and use it to simulate a portion of what we think a part of our energy consumption AI bot we are prototyping would work as a demo for our class, and you can see how that went below 👇
Huggingface - The one stop shop for open access AI models¶
Finally we were shown how to access different models through databases like HuggingFace, how we can run those models, where we can run those models online on server spaces for free and paid so that we don’t have to run them on our own machine because they just wouldn’t and I think that’s just really really cool.
Final Thoughts¶
It’s been a phenomenal week of learning and a lot of information, it’s got me thinking about how we can use these technologies even more in our thesis project, on how we were able to link the energy consumption data we’re receiving from the smart plugs we use to specific AI models for processing, understanding and giving feedback on energy consumption in a way that makes it both interesting and effective.
This is really exciting and something that I think is going to be a real game changer, I think it also opens up a lot of avenues for experimentation for people who aren’t programmers (like me), and in the case of our thesis project, it allows us to take a couple of steps forward in a way that doesn’t require hours and hours of endless programming.
To be able to use these models and understand how they work and link them together to achieve our desired outcome with a very basic understanding of programming, is phenomenal and I’m really excited for it.
It’s a scary future but also a very exciting future and I think with the right tools and the right regulations we’re well on our way to achieving some incredible technological innovations in the next 10 years.